
Textual Analysis & Technology: In Search of a Flexible Solution, Part I
 Post by Kyra Hunting, University of Kentucky
Post by Kyra Hunting, University of Kentucky
This post is part of Antenna’s Digital Tools series, about the technologies and methods that media scholars use to make their research, writing, and teaching more powerful.
2,125… or was that 2,215? When working on my dissertation, a question that came up again and again when I said I was trying to look at entire series of several television shows was “how many episodes did you look at total?” It was a perfectly reasonable question, and yet one I often wasn’t quite sure of the exact number when I was asked it. After a certain point what was another 50 episodes or so? If I couldn’t easily remember the number of episodes I was looking at, I knew remembering the details of each one wasn’t going to be possible. As a result, finding a way to code and take notes on the shows I was examining, and make them searchable later, was one of the first steps I took during my dissertation process. Four years later, as the research approach I developed in my dissertation has become increasingly important to my work, I am still in search of the perfect software.
When I began looking for a solution for my dissertation, I ran into three problems that I suspect are pretty common: 1) I had never worked on a project that size and was not aware that there were software solutions out there; 2) the software I had heard of could cost several hundred dollars; and 3) (most importantly) I wasn’t sure exactly what I was looking for. My dissertation began largely from an interest in finding a different way to approach television texts and wanting to investigate how the form of different television genres and a number of different themes of representation intersected. As a result when I sat down with my first stack of teen drama DVDs to code I didn’t know quite what I wanted to code. It was through the process of coding, thinking about what information I would need and want to be able to go back to, that I learned what I was looking for. I only realized that something like acts of physical affection were something I wanted to code with a simply y/n and character names after 6 episodes. It turned out that a shorthand for demographic information (e.g. WASM for White Adult Straight Man) would be important for medical dramas and crime dramas to denote the demographics of criminals, victims, suspects, and patients, although it had been entirely unnecessary for teen dramas. Coding, for me, was a learning process — something that both recorded information, made it accessible, and helped me discover what I was looking for. That process of discovery through research certainly won’t be foreign to most academics. After all, there is joy in finding that unexpected piece of the puzzle in an archive or watching a focus group coalesce in an unexpected way. However, as I have found half-a-dozen or more software demos later, that is not quite how most academic research software works. Most of the software I experimented with wanted me to know what I was looking for, or at least already have what I was looking at (i.e. interview transcripts, survey results) in a concrete way.
Because of this core issue — the fact that how much information, what information, and what kind was constantly evolving — I found then, and again three years later, that it was an enterprise (read: business) not academic software that best suited my needs. During my dissertation it turned out to be the relatively straightforward Numbers spreadsheet software that did the job. For each genre, I would set up a different spreadsheet with the unique sets of information I needed for that genre. For example, for crime dramas there would be a column for each of the following: demographics of victims(s), demographic(s) of perpetrators, demographics of suspect(s), motive, outcome, religion, non-heteronormative sexuality, gender themes, police behavior, and the nebulous “notes” section that inspired the columns and code short-hands that I needed as things evolved.
What made Numbers work was that I was transparently typing in words, the shorthand I evolved to stand in for the boxes on a traditional “coding” sheet, and numbers (episode numbers, number of patients, etc.). I could always change what I coded and how. Every few episodes I watched I would ask, ‘Is there something important and new I want to track?’ If there was I could word search my notes and assign them shorthands; so, as time went on, I needed less notes and could shorthand much more of my fiftieth ER episode’s notes then I could when I began my fifth. The spreadsheets seemed disorderly and overwhelming to my partner when he peeked at my work (see image below) but they had the advantage of elasticity, changing as I learned what I was doing and what I was looking for.
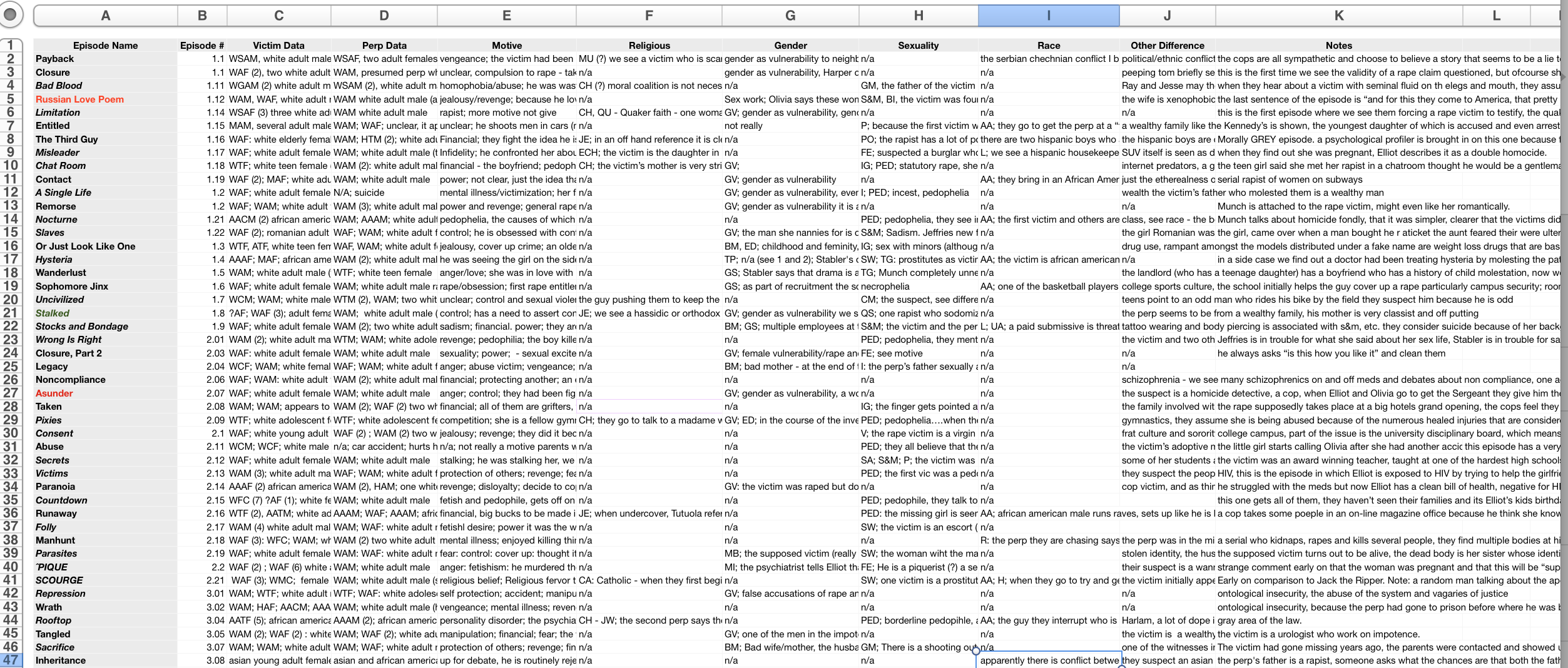
Numbers didn’t have any assumptions (like a lot of more powerful software does) about what information I would be inputting and how I would use it. Therefore, when it came time to sort that information it also leant itself well to finding the relevant episodes and connections. The filter function allowed me to pick any column and any search term and would show me only the rows (episodes) that were relevant. Every episode that contains the word “jealousy” in the motive column but not the words “anger” or “angry” and the religion code “CH” (for Christian) was only a few filter clicks away.
Like Elana Levine, I found that the software that was available couldn’t do the whole job itself. Numbers didn’t really recognize the information I was putting in as something it should count, so if I wanted to know how many white male victims of crimes there were (hint: a lot) I was on my own to physically count them up. As a result I discovered that Zotero, a research material collection system (similar to Scrivener) that I had been using for reading notes and collecting PDFs also helped me analyze those thousands of episodes. After filtering the information using Numbers, I would create files in Zotero where I would list all the episode numbers that discussed Buddhism, or in which a lesbian character appeared, or in which a patient died. I’d then count up the numbers of episodes in a given category. Because Zotero was so searchable, it made it quick and easy to find all the “important themes” a given episode dealt with and calculate all kinds of relationships that I hadn’t originally expected to look at (percentage of patient deaths that were pregnant women? Alcoholics? Coming right up!).
Spreadsheets and a digital version of a filing cabinet (my best way of describing Zotero) are not necessarily the high-tech solutions I might have initially sought but their content agnosticism and searchability made them perfect fits for the work I was doing at the time. Just the other day I pulled up one of my old spreadsheets looking for the sort of thing I hadn’t coded but likely would have kept in the episode notes, and found an episode of a medical drama featuring an elementary school teacher in mere moments. When I started my new job and embarked on new research projects, including those that required collaboration, I started to feel like spreadsheets just wouldn’t do the job anymore and went in search of the perfect software. One year, several meetings with my college’s IT guys, and quite a few demo downloads later and I still haven’t found it. My new, better spreadsheet alternative has turned out to be yet another business solution: FileMaker Pro. And the shoe still doesn’t quite fit, but more on that later (stay tuned for Part II next week).
While I might not have discovered the perfect piece of software, what I have discovered is that the creative use of open-ended software can serve the study of texts well. However, the available research software is not yet designed for the diversity of information, multiplicity of data input types, and unique twists and turns that accompanies the study of media texts.

